



LongCat-2.0:美团今天开源的万亿参数编程模型
2026 年 6 月 30 日,美团 LongCat 团队发布了 LongCat-2.0,一个专为 Agentic Coding 设计的万亿参数开源 MoE 模型,原生支持 100 万 token 上下文,在 SWE-bench Pro 上跑到了 59.5 分,超过了 GPT-5.5 和 Claude Opus 4.6。
核心规格
| 项目 | 参数 |
|---|---|
| 总参数量 | 1.6T(1.6 万亿) |
| 每 token 激活 | 33B–56B(动态),平均 ~48B |
| 上下文长度 | 1M tokens(原生) |
| 架构 | MoE(Mixture of Experts) |
| 训练数据 | 30T+ tokens(中英多语言 + 代码) |
| 算力集群 | 50,000 卡国产算力集群 |
三项关键技术
LongCat Sparse Attention(LSA)— 百万级上下文
传统 Transformer 的注意力复杂度是二次的,token 一多就记不住前面的内容。LSA 用稀疏注意力代替全局注意力——只挑关键信息来关注,复杂度从 O(n²) 降到了 O(n)。模型可以在 100 万 token 范围里精确检索信息,相当于一次看完一套完整代码库。
Zero-Computation Experts + ScMoE
代码任务里,给变量命名和推导递归算法需要完全不同的计算量。LongCat-2.0 做到了 token 级动态激活:
- 简单 token:零计算消耗
- 复杂 token:自动分配更多专家资源(33B–56B 动态范围)
推理时既不浪费算力,该花的地方也不含糊。
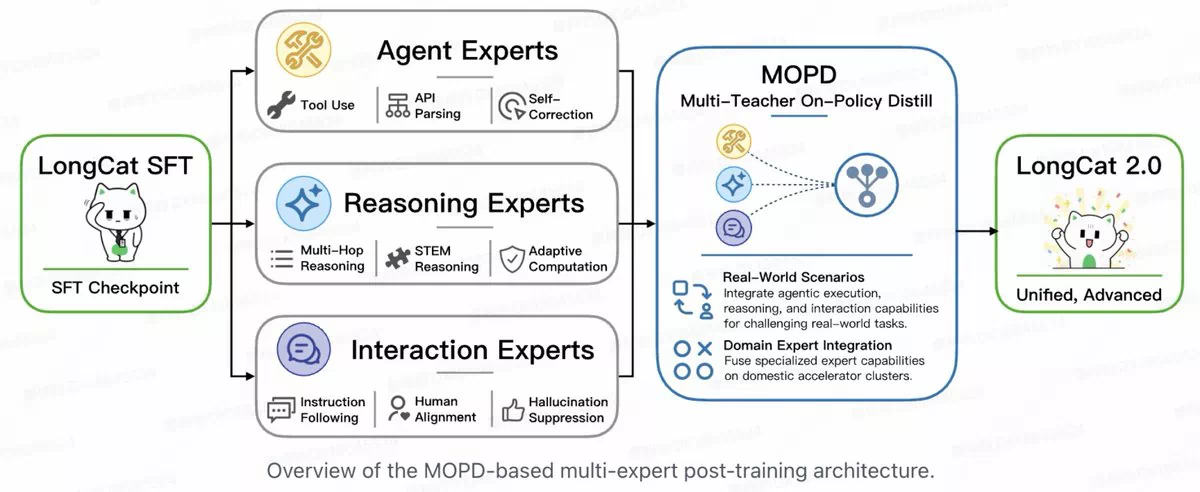
MOPD 多专家融合
LongCat-2.0 从 SFT 检查点出发,分叉训练三类专家,再通过 MOPD 在国产加速器上蒸馏成一个统一模型:
| 专家类型 | 能力 |
|---|---|
| Agent 专家 | 工具调用、API 解析、自我纠错 |
| Reasoning 专家 | 多跳推理、STEM 推理、自适应计算 |
| Interaction 专家 | 指令跟随、人类对齐、幻觉抑制 |
推理时由门控网络根据任务类型动态路由到最合适的专家组合,不是简单合并参数了事。
基准测试
| 基准 | LongCat-2.0 | 对比 |
|---|---|---|
| SWE-bench Pro | 59.5 | 超过 Gemini 3.1 Pro(54.2)、GPT-5.5(58.6)、Claude Opus 4.6(57.3) |
| SWE-bench Multilingual | 77.3 | 和 Claude Opus 4.6(77.8) 差不多 |
| Terminal-Bench 2.1 | 70.8 | 真实终端命令交互 |
| RWSearch | 78.8 | 搜索 Agent 任务 |
| FORTE | 73.2 | 生产力场景 |
| BrowseComp | 79.9 | 复杂浏览与检索 |
实际应用
根据官方放出的案例,LongCat-2.0 能做的事包括:
- Agent 构建:端到端 AI SQL Agent,自然语言查数据,自动规划查询步骤,最后转成业务洞察
- 代码库迁移:分析遗留代码,映射新 SDK API,重构,编译一次性通过
- 完整应用开发:从一句话想法到可运行产品,架构、逻辑、UI 一次生成
- 3D 交互 Demo:自然语言描述直接生成 Three.js 可交互页面
- AI 内容管线:多 Agent 协同写小说,百万 token 上下文保证设定一致性
国产算力训练
LongCat 团队从 2023 年开始搞国产算力,三年从几千卡扩到 5 万卡。解决了算子适配、通信优化和分布式稳定性几个大头问题:
- 稳定性:HCCL 异常处理、弹性伸缩、自动故障恢复——月均故障率降了 70% 以上
- 正确性:自研确定性算子,逐位一致性验证
- 效率:流水调度、内存优化、算子级核心控制——MFU 提升 1.5 倍
- 吞吐:稳态日吞吐超过 1T tokens/天
怎么用
目前已经可以通过几个渠道用上:
- longcat.ai — 在线体验
- OpenRouter — API 访问(全球 Top 3 调用量模型)
- LongCat API 平台 — 兼容 OpenAI / Anthropic API 格式
- 模型权重即将在 Hugging Face / GitHub 开源
几点想法
LongCat-2.0 有几个地方我觉得挺有意思。这是第一个在 5 万卡国产集群上跑通全流程的万亿参数模型,对国内 AI 基础设施来说是个实打实的验证。它选的方向也够准——不追通用对话的 SOTA,专门做 AI 编程,SWE-bench Pro 59.5 的成绩确实有说服力。MOPD 的分治思路也挺聪明,分别训 Agent/Reasoning/Interaction 专家再融合,比从头训一个大模型省事不少。LSA 稀疏注意力也让百万 token 不再只是纸上谈兵,能真的当代码库级理解来用了。
如果你在找一个能帮你写代码、修 bug、重构项目的开源模型,LongCat-2.0 值得试试。