引言:本地 AI 的"灵魂拷问"
随着 DeepSeek R1、Llama 4、Qwen 3.5 等开源大模型不断刷新能力上限,越来越多的开发者和技术爱好者开始尝试本地部署 AI 模型。然而,一个绕不开的问题始终横亘在前:我的硬件到底能不能跑?
你是否曾花数小时下载了一个 70B 参数的模型,结果发现显存不够、推理速度慢到令人崩溃?或者在 Apple Silicon Mac 和 NVIDIA GPU 之间犹豫不决,不知道同样的模型在两种设备上表现差多少?
今天推荐的 CanIRun.ai(https://www.canirun.ai/),正是为了解决这个痛点而生。打开网站,**一键检测,秒出结果**——你的硬件能跑哪些模型、跑得多快、用哪种量化方案最合适,一目了然。
核心功能:四大模块,全面覆盖
CanIRun.ai 的核心体验围绕四个功能模块展开,每一个都精准对准了本地 AI 部署中的实际需求。
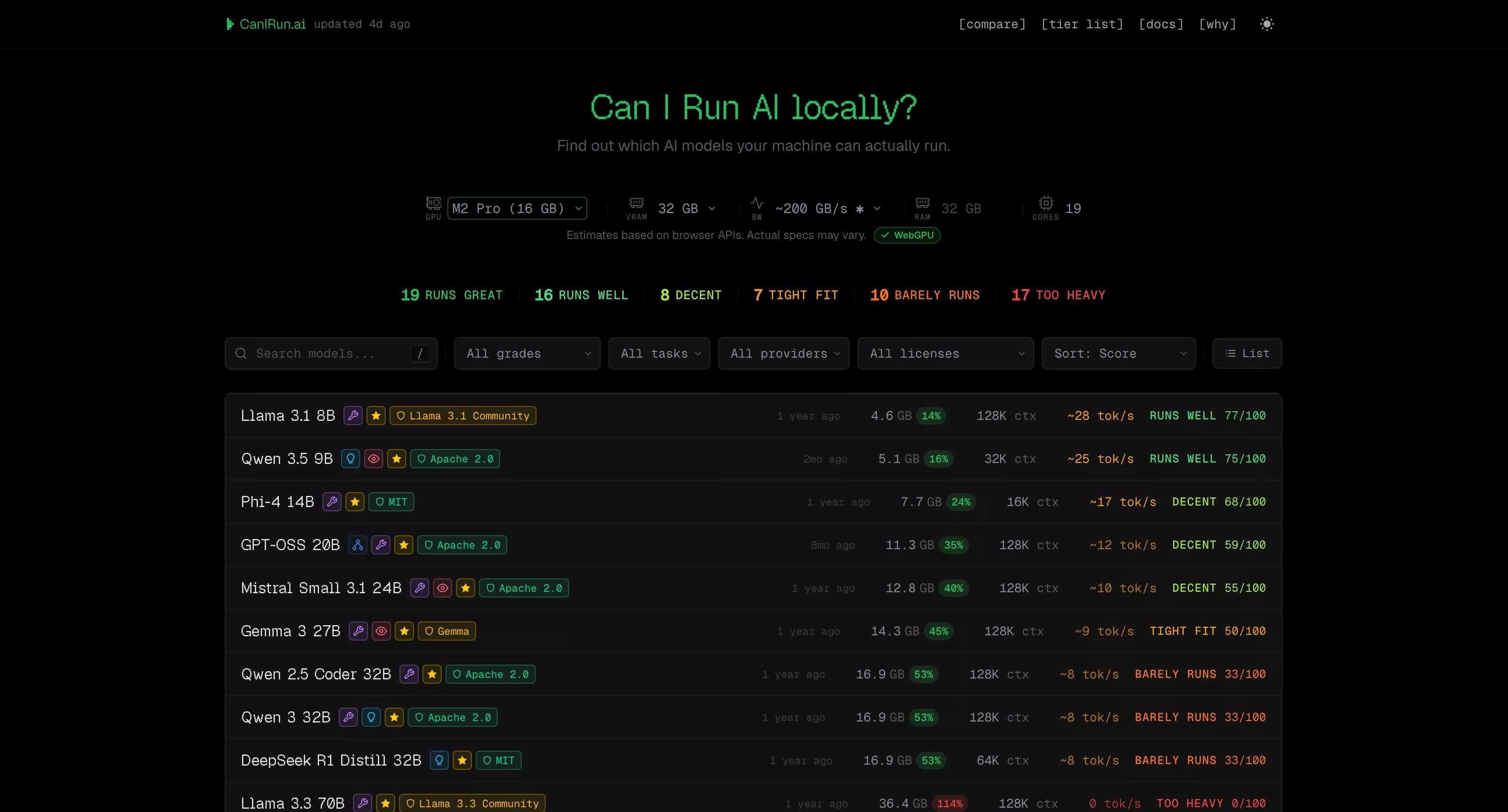
1. 首页模型检测——"我能跑什么?"
打开网站首页,你的浏览器会自动检测 GPU、VRAM、RAM 和 CPU 核心数,然后即时给出一份模型兼容性报告。每个模型被标注为六个等级:
| 等级 | 含义 | 说明 |
|---|---|---|
| S - Runs great | 完美运行 | 快速推理,充裕的显存余量 |
| A - Runs well | 运行良好 | 速度舒适,显存占用合理 |
| B - Decent | 尚可使用 | 可用但体验一般 |
| C - Tight fit | 紧巴巴 | 速度慢,上下文窗口受限 |
| D - Barely runs | 勉强运行 | 输出极慢 |
| F - Too heavy | 跑不动 | 显存装不下 |
网站数据库覆盖了从 0.6B 的 Qwen 3 0.6B 到 1T 参数的 Kimi K2 共 70+ 个主流开源模型,涵盖了 Meta(Llama 系列)、Alibaba(Qwen 系列)、Google(Gemma 系列)、DeepSeek、Microsoft(Phi 系列)、Mistral AI、OpenAI(GPT-OSS)、NVIDIA(Nemotron)等 20+ 家厂商。
筛选功能极为强大:你可以按运行等级(只看能跑的 S/A/B 级)、任务类型(Chat / Code / Reasoning / Vision)、许可证类型(Apache 2.0、MIT、商业可用等)、架构类型(Dense / MoE)进行多维度过滤,还能按评分、参数量、上下文长度、推理速度等排序。
每个模型卡片还展示了 7 种量化级别的显存需求(Q2_K → F16),让你精准选择最适合自己硬件的版本。
2. Tier List 排行榜——"经典 Tier 视角"
/tier 页面将所有模型按照你的硬件表现排列成经典的 S/A/B/C/D/F 分级表,直观展示"哪些是神仙级体验、哪些勉强能用、哪些完全没戏"。支持隐藏 F 级、只看热门模型、下载为图片或复制到剪贴板分享——非常适合发推文或论坛讨论。
3. Compare 设备对比——"A 卡还是 N 卡?Mac 还是 PC?"
/compare 页面允许你选择两台设备进行逐模型对比,系统会自动高亮胜出方。比如你可以直接对比 RTX 4090 vs M4 Max,或者 RTX 4060 vs RX 7900 XTX,一目了然地看到每个模型在两台设备上的运行评分和推理速度差异。
这对于硬件选购决策尤其有价值——在购买新 GPU 或 Mac 之前,先来 CanIRun.ai 对比一下,看看你的目标设备能跑多少个模型、体验如何,远比单纯看参数更有参考意义。
4. Docs 文档——"新手友好,概念清晰"
/docs 页面用简洁的可视化图表解释了本地 AI 的核心概念:
- Parameters(参数量):1-3B 快但弱,70B+ 强但吃硬件,13-34B 是甜点区间
- Quantization(量化):Q4_K_M 是性价比之王(体积缩小至 30%,质量保留 88%),Q8_0 近乎无损,F16 是完整精度
- VRAM(显存):模型必须完整装入显存才能流畅运行,装不下就会退化到 CPU 推理,速度暴跌
- MoE(混合专家模型):如 Mixtral 8x7B 总参数 46.7B 但每次推理只激活 12.9B,兼顾质量和速度,但总参数仍需全部装入显存
- Context Length(上下文长度):128K 上下文约等于 10 万字,但越长越吃内存
- Tokens/s(推理速度):60+ tok/s 即时感,30-60 快速舒适,<5 痛不欲生
- GGUF 格式:llama.cpp / Ollama / LM Studio 通用的量化模型文件格式
- Memory Bandwidth(内存带宽):推理的真正瓶颈——RTX 4090 带宽 1008 GB/s,RTX 4060 仅 272 GB/s,这就是为什么同 VRAM 用量下 4090 快得多
技术原理:浏览器里完成一切,零隐私风险
CanIRun.ai 最令人印象深刻的一点是:所有检测和计算都在你的浏览器本地完成,没有任何数据发送到服务器。
硬件检测三件套
- WebGL:创建隐藏的 WebGL 画布,通过
WEBGL_debug_renderer_info扩展获取 GPU 型号和厂商信息 - WebGPU:如果浏览器支持,请求适配器获取额外的设备和架构详情
- Navigator API:
navigator.hardwareConcurrency获取 CPU 核心数,navigator.deviceMemory获取近似 RAM 容量,还运行一个约 30ms 的 CPU 微基准测试估算单核性能
GPU 数据库
检测到 GPU 后,在内置数据库中查找匹配的 ~40 款 NVIDIA/AMD/Intel GPU 和 ~12 款 Apple Silicon 芯片,获取 VRAM 容量和内存带宽两个关键参数。
评分算法
综合评分(0-100)由三大因素构成:
- 速度评分(55% 权重):基于 GPU 内存带宽和模型显存占用估算 tok/s,80+ tok/s 得 100 分,<5 tok/s 仅 10 分
- 显存余量(35% 权重):模型占用显存越少,余量越充裕,得分越高
- 质量加成(约 10%):更大参数量的模型获得小幅加成(上限 15 分),体现"大模型更聪明"的常识
特别地,如果模型只能"紧巴巴"地塞进显存,总分会被乘以 0.65 的惩罚系数,警示你实际体验可能远不如分数所示。
Apple Silicon 特殊处理
Apple Silicon Mac 采用统一内存架构,CPU 和 GPU 共享内存。CanIRun.ai 将可用内存上限设为总 RAM 的 75%(再乘以 70% 的安全系数),这意味着一台 36GB 的 MacBook Pro 实际可用约 27GB 来跑模型——远超普通 8GB 显卡的能力。
模型库:紧跟前沿,持续更新
CanIRun.ai 的模型库更新非常及时,截至撰稿时已包含以下最新模型:
- Gemma 4 系列(E2B / E4B / 26B-A4B / 31B,2026 年 4 月发布,5 天前更新)
- GPT-OSS 20B / 120B(OpenAI 首个开源权重模型,Apache 2.0 许可)
- DeepSeek V3.2(685B 参数,当前最强 MoE 之一)
- Qwen 3.5 系列(0.8B 到 397B-A17B,原生多模态)
- Kimi K2(1T 参数,384 个专家的巨型 MoE)
- Devstral 2 123B(Mistral 专为代码设计,SWE-bench 72.2%)
- Llama 4 Scout / Maverick(Meta 最新 MoE 架构)
数据来源包括 HuggingFace API(下载量、点赞数)、Ollama Library(拉取次数和可用变体)以及模型官方论文和公告,在每次构建时自动拉取更新。
谁适合用?使用场景一览
| 用户类型 | 典型场景 |
|---|---|
| AI 入门者 | "我刚买了 RTX 4060,能跑什么模型?"——打开即知 |
| 硬件选购者 | "加 2000 块从 4060 升到 4070,体验差距多大?"——Compare 对比 |
| Mac 用户 | "M4 Pro 24GB 能跑 DeepSeek R1 吗?"——即时检测 |
| 模型开发者 | "我的新模型 Q4 量化后需要多少显存?"——查看各量化级别 |
| 技术内容创作者 | "想做个 GPU 横评,需要直观的对比图"——Tier List 导出 |
优点与局限
👍 值得称赞的:
- 零门槛:无需注册、无需安装、无需下载,打开浏览器就能用
- 隐私安全:所有计算在本地完成,硬件信息不会上传
- 模型覆盖广:70+ 模型,7 种量化级别,持续更新
- 教育价值高:Docs 页面是本地 AI 入门的优秀教材
- 免费开源:由 midudev 为本地 AI 社区构建,完全免费
- 设计精良:深色/浅色主题切换,移动端适配,交互流畅
⚠️ 需要注意的:
- 结果为估算值:浏览器 API 提供的硬件信息有限,GPU 名称可能模糊,RAM 数值为近似值,实际性能受散热降频、后台进程、驱动版本等多因素影响,误差可能达 ±20%
- GPU 数据库有限:约 40 款桌面 GPU + 12 款 Apple Silicon,部分老型号或小众 GPU 可能无法识别
- 不支持多 GPU 配置:目前仅检测单 GPU 场景
- Linux 用户可能检测不到 GPU:部分 Linux 浏览器的 WebGL/WebGPU 支持受限
总结与展望
CanIRun.ai 用最简单的方式回答了本地 AI 最常被问到的问题。它不需要你翻阅冗长的模型文档、不需要你手动计算 VRAM 需求、不需要你在 Reddit 或论坛上等回复——打开网页,答案就在眼前。
随着开源大模型的爆发式增长和本地部署工具(Ollama、LM Studio、llama.cpp)的日益成熟,像 CanIRun.ai 这样的"硬件-模型匹配器"将从锦上添花变为刚需工具。未来如果加入多 GPU 支持、自定义硬件配置、模型性能基准测试等进阶功能,它的价值还将进一步放大。
无论你是刚接触本地 AI 的新手,还是经验丰富的部署老手,CanIRun.ai 都值得加入你的书签栏。
