



技术架构与核心突破
GPT-5.5是OpenAI自GPT-4.5以来首次全量重训的基座模型,并非简单的小版本迭代,而是一次底层架构的重构。该模型与英伟达GB200/GB300 NVL72系统联合设计,从训练到部署实现了硬件与软件的深度协同优化。
最引人注目的突破在于效率与智能的平衡。尽管模型规模更大、能力更强,GPT-5.5在实际服务中保持了与GPT-5.4相同的每token延迟。更关键的是,在完成相同Codex任务时,GPT-5.5消耗的token数量显著减少,在NVIDIA GB200 NVL72系统上,每百万token的推理成本降至前代的1/35。
性能表现全面超越
GPT-5.5在多个关键基准测试中全面超越GPT-5.4,特别是在长程任务和智能体能力方面表现突出:
| 评测项目 | GPT-5.5 | GPT-5.4 | 提升幅度 | 测试内容 |
|---|---|---|---|---|
| Terminal-Bench 2.0 | 82.7% | 75.1% | +7.6% | 复杂命令行工作流 |
| Expert-SWE | 73.1% | 68.5% | +4.6% | 长周期工程任务 |
| SWE-Bench Pro | 58.6% | 57.7% | +0.9% | 真实GitHub问题修复 |
| GDPval | 84.9% | 83.0% | +1.9% | 44种职业知识工作 |
| OSWorld-Verified | 78.7% | 75.0% | +3.7% | 真实计算机操作 |
| Tau2-bench Telecom | 98.0% | 92.8% | +5.2% | 复杂客服工作流 |
| MRCR v2 512K-1M | 74.0% | 36.6% | +37.4% | 长文本多点检索 |
| Graphwalks BFS 1M | 45.4% | 9.4% | +36.0% | 长上下文结构追踪 |
| FrontierMath Tier 4 | 35.4% | 27.1% | +8.3% | 高难度数学任务 |
| BixBench | 80.5% | 74.0% | +6.5% | 生物信息学分析 |
| GeneBench | 25.0% | 19.0% | +6.0% | 基因数据分析 |
数据来源:OpenAI官方发布及第三方评测
智能体能力的质变
GPT-5.5的核心设计理念从"能力集合"转向"工作系统"。用户可以将杂乱、多步骤的复杂任务直接抛给模型,由它自主规划路径、调用工具、校验结果、消解歧义,并持续推进直至完成。
在编程领域,这一变化尤为明显。早期测试者反馈,GPT-5.5在理解大型代码库整体结构方面明显更强,能主动预判潜在问题,提前考虑测试和审查需求,无需额外提示。英伟达一位工程师在早期测试后表示:"失去GPT-5.5的访问权限,感觉就像肢体被截肢了一样"。
长上下文能力的实质性突破
虽然GPT-5.4也号称支持100万token上下文,但在超长文本检索上表现不佳(512K-1M范围仅36.6%)。GPT-5.5将这一数字提升至74.0%,提升了37.4个百分点,使得1M上下文窗口真正具备了实用价值。
这一突破对于需要处理大型代码库、长文档分析的场景具有革命性意义。Codex环境支持400K上下文窗口,API版本支持1M上下文(需显式配置),最大输出达到131,072 tokens。
科研与知识工作的新高度
在科学研究领域,GPT-5.5展现出令人印象深刻的能力。一版内部模型成功证明了一个关于Ramsey数的长期猜想,并在证明助手Lean中完成了形式化验证。Ramsey数是组合数学中的核心研究对象,相关成果通常技术难度极高且罕见。
在生物信息学评测BixBench中,GPT-5.5以80.5%的得分位列所有已公布成绩的模型之首。Jackson Laboratory for Genomic Medicine的免疫学教授Derya Unutmaz使用GPT-5.5 Pro分析了一个包含62个样本和近28,000个基因的基因表达数据集,生成了详细的研究报告,他表示这项工作原本需要团队数月时间。
定价策略与市场定位
GPT-5.5的API定价为每百万token输入5美元、输出30美元,是GPT-5.4(输入2.50美元、输出15美元)的两倍。GPT-5.5 Pro的API定价更高,为每百万token输入30美元、输出180美元。
然而,OpenAI强调,由于GPT-5.5完成相同任务所需的token数量大幅减少,综合使用成本未必显著上升。批量处理和弹性定价享受半价优惠,优先处理为标准价格的2.5倍。
可用性与部署
目前,GPT-5.5已向ChatGPT Plus、Pro、Business和Enterprise用户开放,在ChatGPT中以"GPT-5.5 Thinking"形式上线。Codex支持最高400K的上下文窗口。API版本即将上线,标准定价方案是每百万输入token 5美元、每百万输出token 30美元。
安全与治理
GPT-5.5经过了OpenAI最严格的安全评估流程,包括预备框架评估、领域特定测试、针对高级生物学和网络安全能力的新针对性评估,以及与外部专家的稳健测试。OpenAI将GPT-5.5的生物/化学和网络安全能力归类为"高"级别,虽然未达到"关键"级别,但其网络安全能力相比GPT-5.4有明显提升。
行业影响与竞争格局
GPT-5.5的发布正值Anthropic在私募二级市场估值突破1万亿美元之际,而OpenAI今年3月末的最新一轮融资估值仍停留在8520亿美元。这一发布被视为OpenAI对竞争压力的直接回应。
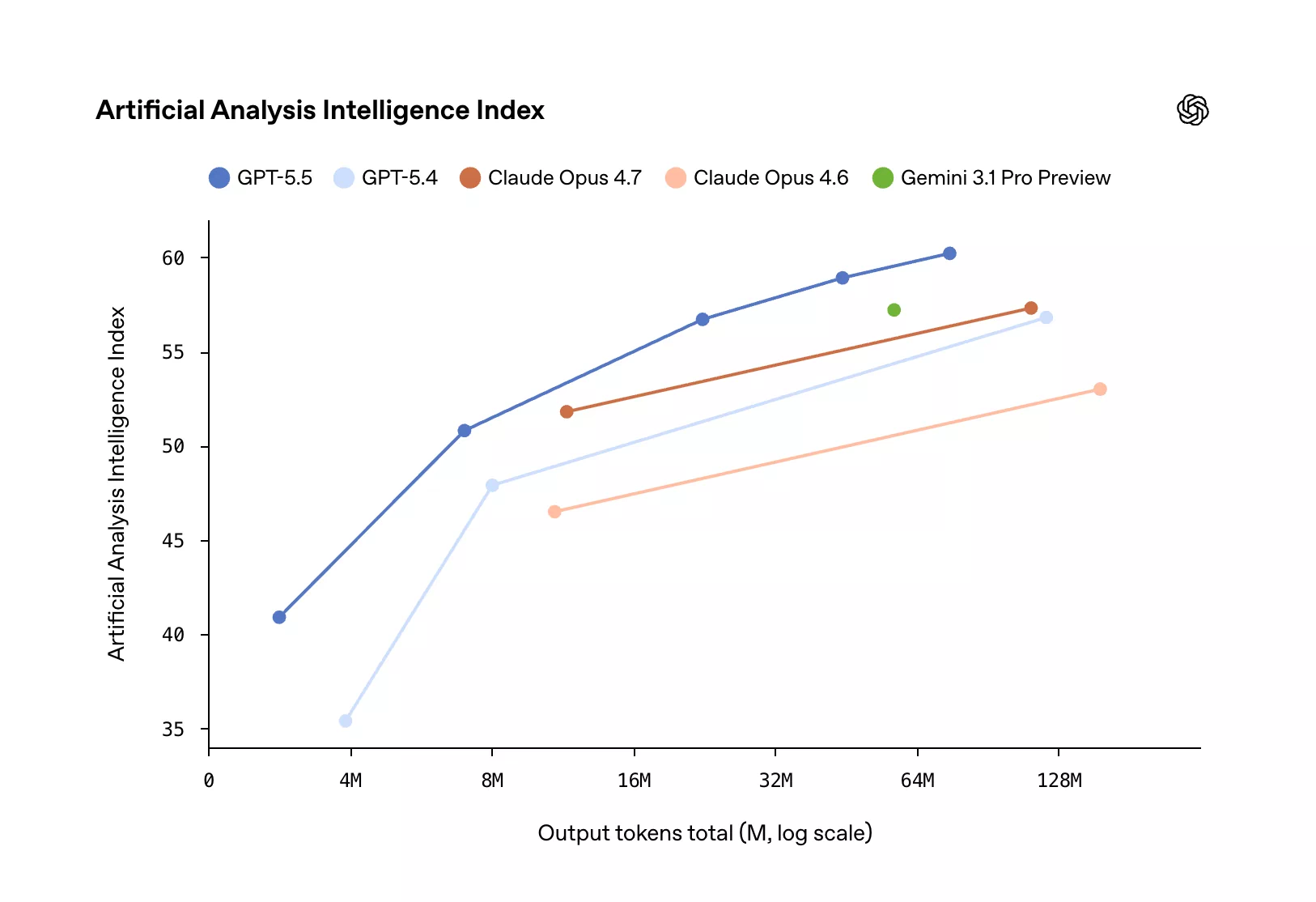
在第三方评测机构Artificial Analysis的综合智能指数榜单上,OpenAI凭借GPT-5.5系列拿下了第一名和第二名,前六席中包揽了四席。不过,在SWE-Bench Pro(评估真实GitHub问题解决能力)上,Claude Opus 4.7仍以64.3%的得分领先于GPT-5.5的58.6%。
未来展望
GPT-5.5代表了AI从辅助工具向协作伙伴的转变。它不再仅仅是回答问题的引擎,而是能够理解复杂目标、自主规划执行路径、持续推进直至任务完成的智能体。随着模型在代码编写、科学研究、知识工作等领域的深度应用,GPT-5.5有望重新定义人机协作的工作模式。
OpenAI总裁Greg Brockman强调,GPT-5.5的核心突破在于能够以更少的指导完成更多任务,最大的亮点在于处理模糊问题时展现出更强的自主性。这一特性使得GPT-5.5不仅是一个更强大的模型,更是一个全新的工作范式。
随着GPT-5.5的全面部署,AI行业正式进入了"智能体时代",模型不再仅仅是执行指令的工具,而是能够理解意图、规划路径、自主执行的合作伙伴。这一转变将对软件开发、科学研究、企业运营等各个领域产生深远影响。
模型低价使用
还在为模型选型与接入调试而烦恼?LinkThinkAI 为您提供一站式解决方案。
我们现已全面支持 DeepSeek-V4、GPT-5.5 及 GPT-Image-2 等前沿模型。通过我们统一对齐 OpenAI 风格的 API,您只需更改 Base URL 即可快速切换与上线,极大降低了集成与迁移成本。
现在注册,通过本平台调用 GPT 系列模型,可享独家 7.5 折优惠,助您以更低的成本体验顶级模型能力。
我们的平台为您整合了多家供应商与多模态能力,提供:
- 灵活路由:支持通道、分组与回退策略配置,保障服务高可用。
- 成本清晰:通过模型倍率、用量统计与分组策略,让预算与账单一目了然。
- 简单接入:从创建账号到首次成功调用,步骤清晰简单。
告别繁琐的逐个对接,用一份文档、一个密钥管理所有模型。立即访问 https://linkthinkai.com ,开启高效、稳定、高性价比的模型调用之旅。