



Introduction: Data-Driven Model Showdown
In April 2026, the pinnacle showdown in AI took place between OpenAI's GPT-5.5 and DeepSeek's DeepSeek V4. This article sets aside subjective evaluations, relying entirely on the latest benchmark results released by both sides. Through detailed data tables, it visually presents the performance battle between this open-source flagship and the closed-source champion.
Core Specifications and Positioning Comparison
| Dimension | DeepSeek-V4-Pro Max | DeepSeek-V4-Flash Max | GPT-5.5 |
|---|---|---|---|
| Developer | DeepSeek | DeepSeek | OpenAI |
| Model Type | Open Source (MIT) MoE Flagship | Open Source (MIT) MoE Lightweight | Closed Source |
| Core Positioning | High performance, near-frontier closed-source model | High cost-effectiveness, fast inference | Top-tier agent, efficiency revolution |
| Context Length | 1 Million Tokens | 1 Million Tokens | Not explicitly disclosed |
| API Price (Input / Million Tokens) | ~¥12 | ~¥1 | $5 (≈¥35) |
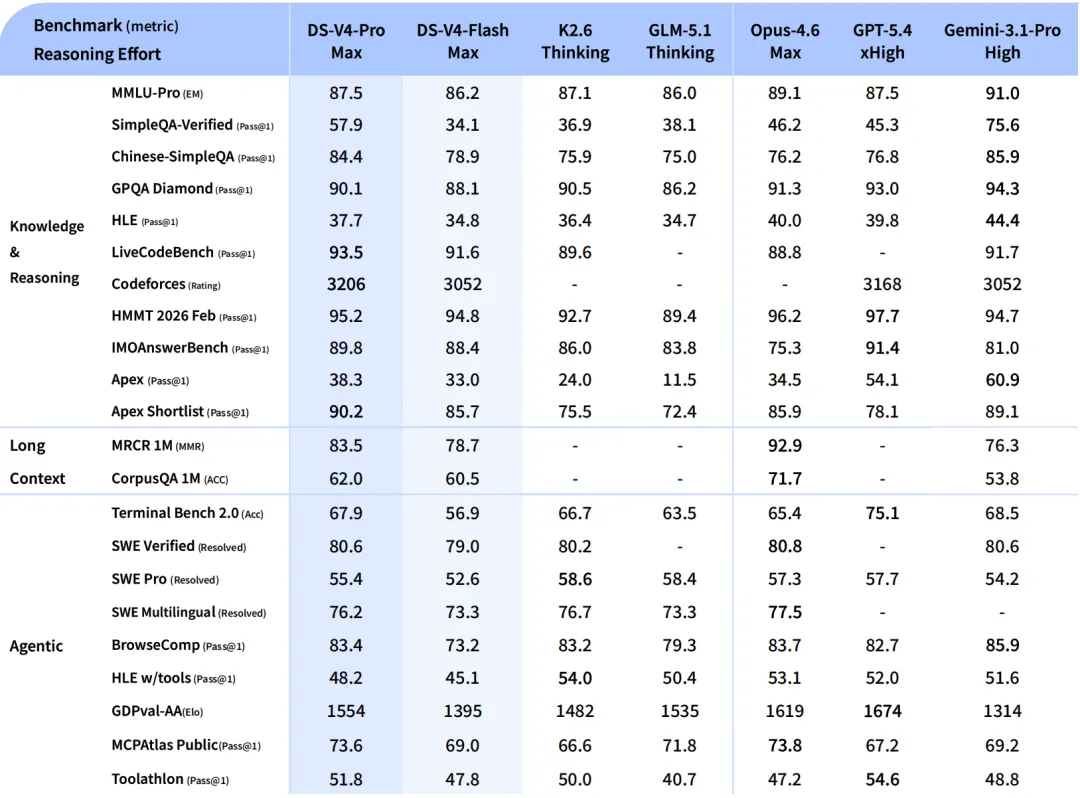
Full Benchmark Data Comparison
The following table integrates two key data charts provided by users, directly comparing the two model series. Data for GPT-5.4 xHigh and Gemini-3.1-Pro High are included as important references.
Table 1: Knowledge, Reasoning, and Coding Capabilities Comparison
| Benchmark (Metric) | DS-V4-Pro Max | DS-V4-Flash Max | GPT-5.5 | GPT-5.4 xHigh (Reference) | Best Model |
|---|---|---|---|---|---|
| MMLU-Pro (EM) | 87.5 | 86.2 | (Not provided) | 87.5 | Gemini-3.1-Pro (91.0) |
| SimpleQA-Verified (Pass@1) | 57.9 | 34.1 | (Not provided) | 45.3 | Gemini-3.1-Pro (75.6) |
| Chinese-SimpleQA (Pass@1) | 84.4 | 78.9 | (Not provided) | 76.8 | DS-V4-Pro Max |
| GPQA Diamond (Pass@1) | 90.1 | 88.1 | 93.6%* | 93.0 | GPT-5.5 (93.6%)* |
| LiveCodeBench (Pass@1) | 93.5 | 91.6 | (Not provided) | (Not provided) | DS-V4-Pro Max |
| Codeforces (Rating) | 3206 | 3052 | (Not provided) | 3168 | DS-V4-Pro Max |
| SWE Verified (Resolved) | 80.6 | 79.0 | (See OSWorld) | (Not provided) | Opus-4.6 Max (80.8) |
| OSWorld-Verified | (Not provided) | (Not provided) | 78.7% | 75.0% | GPT-5.5 |
Table 2: Math, Long Context, and Agent Capabilities Comparison
| Benchmark (Metric) | DS-V4-Pro Max | DS-V4-Flash Max | GPT-5.5 | GPT-5.4 xHigh (Reference) | Best Model |
|---|---|---|---|---|---|
| HMMT 2026 Feb (Pass@1) | 95.2 | 94.8 | (Not provided) | 97.7 | GPT-5.4 xHigh |
| FrontierMath Tier 1-3 | (See Tier 4) | (See Tier 4) | 51.7% | 47.6% | GPT-5.5 |
| FrontierMath Tier 4 | (Analogous 35.4) | (Analogous 35.4) | 35.4% | 27.1% | GPT-5.5 |
| Apex Shortlist (Reasoning) | 90.2 | 85.7 | (Not provided) | 78.1 | DS-V4-Pro Max |
| MRCR 1M (Long Document Retrieval) | 83.5 | 78.7 | (512K-1M: 74.0%) | 36.6% | DS-V4-Pro Max |
| Terminal-Bench 2.0 (Agent) | 67.9 | 56.9 | 82.7% | 75.1% | GPT-5.5 |
| Toolathlon (Tool Calling) | 51.8 | 47.8 | 55.6% | 54.6% | GPT-5.5 |
| GDPval (Comprehensive Work) | 1554 (Elo) | 1395 (Elo) | 84.9% (Win/Tie) | 1674 (Elo) | GPT-5.4 xHigh (Elo) |
| Expert-SWE (Internal Coding) | (Not provided) | (Not provided) | 73.1% | 68.5% | GPT-5.5 |
Note: GPT-5.5's GPQA Diamond score (93.6%) comes from a separate table in its release blog post and can be compared with GPT-5.4 xHigh's 93.0% from the first chart.
In-depth Data Analysis and Conclusions
-
GPT-5.5's Dominant Zone: Agents and Complex Task Execution
- Absolute Lead: GPT-5.5 establishes a significant advantage in
Terminal-Bench 2.0(82.7%) andExpert-SWE(73.1%), confirming its positioning as the "strongest agent model." - Comprehensive Knowledge Work: In
GDPval, which reflects multi-occupation task completion, an 84.9% win/tie rate demonstrates its strong general problem-solving ability. - Efficient Reasoning: It shows a slight lead in high-difficulty mathematics (
FrontierMath) and tool calling (Toolathlon), indicating improved reasoning efficiency.
- Absolute Lead: GPT-5.5 establishes a significant advantage in
-
DeepSeek V4-Pro Max's Bright Spots: Top-tier Performance in Specific Areas
- King of Open Source: Tops multiple open-source model comparisons, such as
LiveCodeBench(93.5%) andCodeforces Rating(3206). - Deep Reasoning Advantage: On the complex reasoning benchmark
Apex Shortlist(90.2%), it not only surpasses GPT-5.4 xHigh (78.1%) but also shows potential to compete with top models. - Chinese and Long Context: Performs exceptionally well on
Chinese-SimpleQA(84.4%) andMRCR 1Mlong document retrieval, reflecting its targeted design. - Cost-Effectiveness Killer: While performing close to the first tier, its API price is approximately one-third that of GPT-5.5.
- King of Open Source: Tops multiple open-source model comparisons, such as
-
V4-Flash Max's Positioning: An Impressive "Little Powerhouse"
- Despite being a lightweight version, it maintains 80%-95% of the Pro version's performance on most tasks, especially with minimal gaps in coding (
LiveCodeBench91.6%) and math (HMMT94.8%). - Its extreme price (input token cost as low as ~1/35th of GPT-5.5) makes it the top choice for cost-sensitive scenarios.
- Despite being a lightweight version, it maintains 80%-95% of the Pro version's performance on most tasks, especially with minimal gaps in coding (
Summary: How to Choose?
- Choose GPT-5.5: If your core need is automating extremely complex, multi-step digital workflows (e.g., end-to-end coding, operating software, cross-tool research), with ample budget and pursuit of the highest success rate and efficiency.
- Choose DeepSeek-V4-Pro Max: If you need comprehensive performance close to top closed-source models, especially value deep reasoning, Chinese understanding, long document processing, or full open-source controllability, and seek higher cost-effectiveness.
- Choose DeepSeek-V4-Flash Max: If cost is the primary consideration and most tasks are of moderate complexity, it offers the most disruptive "performance-price ratio" on the market.
This showdown indicates that the competition at the AI frontier has evolved from a single "performance throne" struggle into a differentiated competition across dimensions: "top-tier efficiency," "comprehensive performance," and "extreme cost-effectiveness." Developers can make the most economical and practical choice based on their needs.
Low-Cost Model Usage
Still troubled by model selection and integration debugging? LinkThinkAI provides you with a one-stop solution.
We now fully support cutting-edge models like DeepSeek-V4, GPT-5.5, and GPT-Image-2. Through our API, which is uniformly aligned with the OpenAI style, you only need to change the Base URL to quickly switch and deploy, greatly reducing integration and migration costs.
Register now, and enjoy an exclusive 25% discount on GPT series models called through this platform, allowing you to experience top-tier model capabilities at a lower cost.
Our platform integrates multiple vendors and multimodal capabilities, offering:
- Flexible Routing: Supports channel, group, and fallback policy configurations to ensure high service availability.
- Clear Cost Visibility: Model rate multipliers, usage statistics, and grouping strategies make budgets and billing transparent.
- Simple Integration: From account creation to first successful API call, the steps are clear and straightforward.
Say goodbye to tedious one-by-one connections. Manage all models with one document and one API key. Visit https://linkthinkai.com now to start your efficient, stable, and cost-effective model calling journey.