



LongCat-2.0: Meituan's Open-Source Trillion-Parameter Coding Model
On June 30, 2026, Meituan's LongCat team officially released LongCat-2.0, a trillion-parameter open-source MoE model built for agentic coding. It natively supports 1M token context and scored 59.5 on SWE-bench Pro, surpassing GPT-5.5 and Claude Opus 4.6.
Key Specs
| Spec | Value |
|---|---|
| Total Parameters | 1.6T (1.6 trillion) |
| Active per Token | 33B–56B (dynamic), ~48B avg |
| Context Length | 1M tokens (native) |
| Architecture | MoE (Mixture of Experts) |
| Training Data | 30T+ tokens (Chinese, English, multilingual, code) |
| Compute Cluster | 50,000 domestic AI accelerators |
Three Key Technical Innovations
LongCat Sparse Attention (LSA)
Traditional attention mechanisms scale quadratically — beyond ~100K tokens, models start forgetting. LSA uses sparse attention to selectively attend to key information, dropping complexity from O(n²) to O(n). This enables accurate retrieval across 1 million tokens — equivalent to browsing an entire codebase at once.
Zero-Computation Experts + ScMoE
Code tasks vary wildly in complexity. LongCat-2.0 achieves token-level dynamic activation: simple tokens cost zero compute, while complex tokens automatically receive more expert resources (33B–56B range).
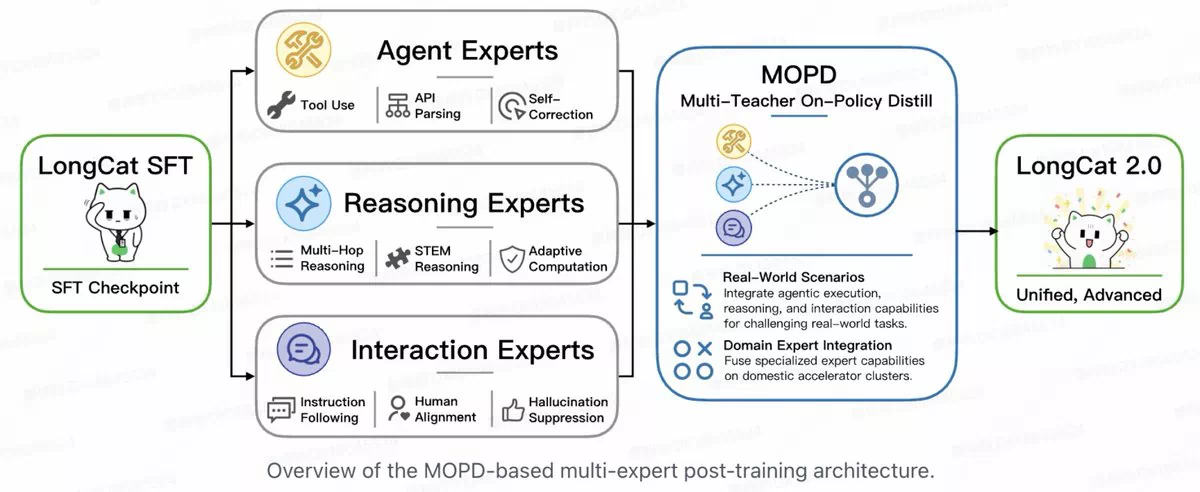
MOPD Multi-Expert Fusion
LongCat-2.0 starts from an SFT checkpoint, branches into three specialized expert groups (Agent, Reasoning, Interaction), then distills them into one unified model via MOPD on domestic accelerator clusters.
Benchmarks
| Benchmark | LongCat-2.0 | Comparison |
|---|---|---|
| SWE-bench Pro | 59.5 | Beats Gemini 3.1 Pro (54.2), GPT-5.5 (58.6), Claude Opus 4.6 (57.3) |
| SWE-bench Multilingual | 77.3 | On par with Claude Opus 4.6 (77.8) |
| Terminal-Bench 2.1 | 70.8 | Real terminal interaction |
| RWSearch | 78.8 | Search agent tasks |
| FORTE | 73.2 | Productivity scenarios |
| BrowseComp | 79.9 | Complex browsing |
How to Access
- longcat.ai — online experience
- OpenRouter — global API (Top 3 by call volume)
- LongCat API Platform — OpenAI / Anthropic API compatible
- Model weights coming soon on Hugging Face / GitHub